Merger trees
Within the currently accepted ΛCDM cosmology, dark matter halos merge from small clumps to ever larger objects. This merging history can also be traced in cosmological simulations and stored in the form of merger trees (see illustration below). In order to store such merger trees in our database, we closely follow the guidelines that had been provided by the Millennium Run Database. Thus, experienced Millennium DB users will have no difficulties to adapt to our format. Merger trees are built for each halo or FOF group which exists at redshift 0 and exceeds a certain mass limit (given in the documentation for the corresponding database table, see e.g. for MDR1 FOFMtree-Table). From this root-halo (at the top in the illustration below), the branches go to each of its progenitors, reaching backwards in time, with the most massive progenitor being visited first (Main branch). Once the tree is built, we walk its nodes according to a depth-first search and attach to each node its rank. This rank is added to the identifier of the tree root (treerootid) to construct a unique id for each halo/FOF group, thus allowing quick access to the complete tree for each halo. The identifiers used in the database to simplify and accelerate such SQL queries are explained below.
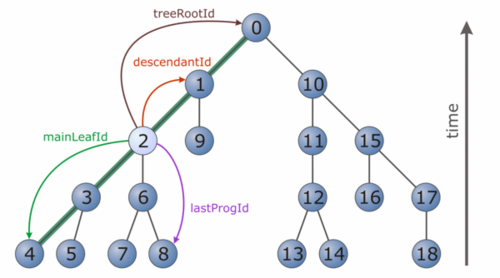
Merger tree: the top node (root) of the tree represents a halo or FOF group at redshift 0. From there branches reach backwards in time to its progenitors, i.e. the timeline goes here from bottom to top. The numbers at each node indicate the depth-first order, with the most massive progenitors being on the leftmost side of each sub-tree. These form the main branch (e.g. thick green line for tree root (0)) of the corresponding node. The identifiers (ids) drawn here for one example node (2) are stored in the database table and explained below.
treerootid
This is the id of the top node in the merger tree, i.e. the final descendant at redshift 0 (treeSnapnum = 39 for MDR1). The id is calculated based on the number of the halo/FOF group in the corresponding halo catalogue (starting line numbers with 0):
treerootid = (rank in file + 1) * 10^8
The power of ten here may vary for each FOFMtree table, since it must be big enough to include all halos for a given tree.
foftreeid, lastprogid and descendantId
The foftreeids are the unique object identifiers in the FOF merger tree database table. For BDM halos, we will use bdmTreeId as the corresponding identifier (once the BDM merger trees are available). For this documentation, we will now use foftreeid for all further explanations. In order to encode the tree membership, we just add the halo’s/group’s rank in the merger tree to the corresponding treerootid:
foftreeid = treerootid + (rank in merger tree)
For enabling quick and simple queries of halos/FOF groups and their merging history, we store in the database table for each object its foftreeid and additionally its treerootid as well as the id of the direct descendant (forward in time, descendantId) and also the id of the last progenitor in the merger tree (lastprogid). Since the depth-first-order rank is encoded in the foftreeid, all progenitors of a halo/FOF group can be found based on the lastprogid: the progenitors of a given halo/group have foftreeids between the id of the halo/group and its lastprogid:
SELECT * FROM <tablename>
WHERE foftreeid BETWEEN <node_foftreeid> AND <node_lastprogid>
where <node_foftreeid> is the foftreeid of the given dark matter halo or FOF group and <node_lastprogid> is the id of its last progenitor (lastprogid).
Main branch
The main branch of a halo or FOF groups goes along the most massive progenitors and allows users to trace e.g. the mass accretion history or follow other properties of a halo/FOF group with time. The important id for retrieving the main branch is the mainLeafId, which stores the id of the last progenitor on the main branch. The foftreeids are arranged such that the main branch always goes along the leftmost progenitors. Thus one can easily extract the main branch of a halo/FOF group with a given foftreeid as:
SELECT * FROM <tablename>
WHERE foftreeid BETWEEN <node_foftreeid> AND <node_mainLeafId>
where <node_foftreeid> and <node_mainLeafId> are the ids of the interesting node and the id of its last leaf on the main branch. This query can also be rewritten by joining the table with itself:
SELECT prog.* FROM <tablename> prog, <tablename> descend
WHERE descend.foftreeid = <node_foftreeid>
AND prog.foftreeid BETWEEN descend.foftreeid AND descend.mainLeafId
ORDER BY prog.foftreeid ASC
The server will reorder this query so that first the required mainleafid and foftreeid are selected and then this result is joined with the full table to retrieve the main branch progenitors. Thus, it is equivalent to this query:
SELECT prog.* FROM <tablename> AS prog,
( SELECT foftreeid, mainLeafId FROM <tablename> WHERE foftreeid = <node_foftreeid> ) AS descend
WHERE prog.foftreeid BETWEEN descend.foftreeid AND descend.mainLeafId
ORDER BY prog.foftreeid ASC